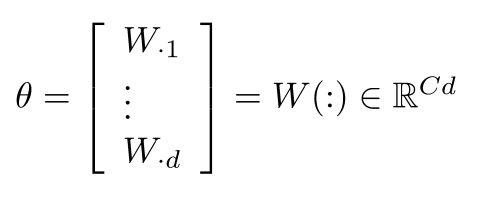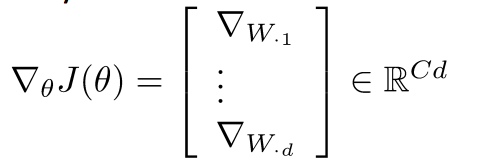机器学习优化问题
机器学习优化问题
引入词向量
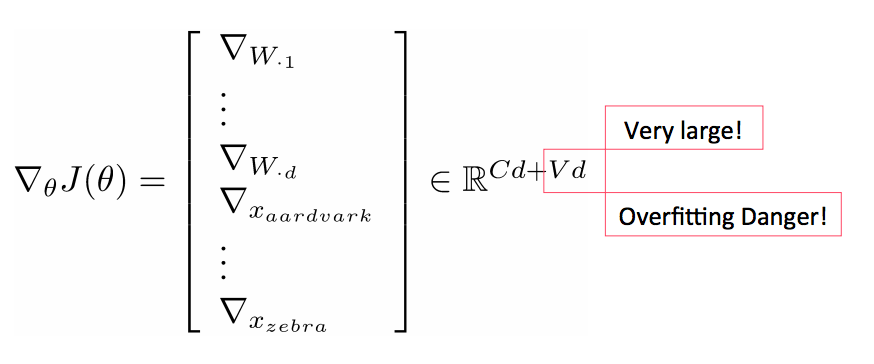
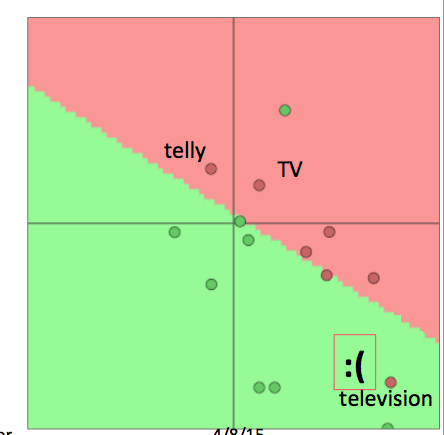
重新训练词向量会丧失泛化能力
重新训练词向量会丧失泛化能力续
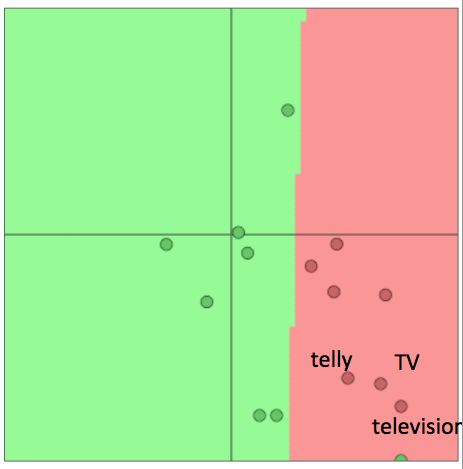
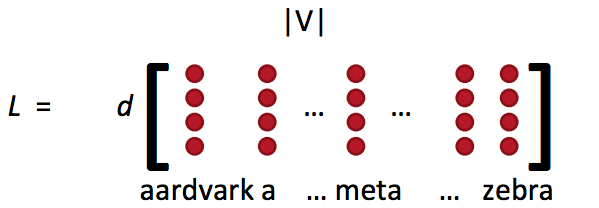
词向量概念回顾
|
 /2
/2 


 关注微博
关注微博 关注我们
关注我们
 |广告服务|关于我们|Archiver|手机版|小黑屋|大数据人
( 鄂ICP备14012176号-2 )
|广告服务|关于我们|Archiver|手机版|小黑屋|大数据人
( 鄂ICP备14012176号-2 ) 
GMT+8, 2024-4-29 05:15 , Processed in 0.192058 second(s), 21 queries .
Powered by 小雄! X3.2
© 2014-2020 bigdataer Inc.